Не может быть! Он же раз в 100 мощнее eBox, как так?Serge wrote:Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz
Kolibri Graphics Benchmark (MGB)
-
-
 yogev_ezra Public Relations
yogev_ezra Public Relations - Posts 1879
- Joined: Mon Jun 07, 2010 12:01 pm

-
yogev_ezra
Тут дело не в процессоре, а в том как и через что реализован обмен с памятью для видео.
Тут дело не в процессоре, а в том как и через что реализован обмен с памятью для видео.
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
Radeon HD 7770. Слева результаты с загруженным atikms
-
1.png (4 KiB)Viewed 7907 times
SVN r. 3377 - добавлен бенчмарк для ф.36 (прочитать область экрана).
Теперь можно оценить насколько скорость чтения из видеопамяти отстает от скорости записи в нее.
Roverbook U800
Dell Inspiron N7010 (Intel i5)
Два столбца замеров - это просто два последовательных запуска.
Теперь можно оценить насколько скорость чтения из видеопамяти отстает от скорости записи в нее.
Roverbook U800
Spoiler:
-
U800.png (6.6 KiB)Viewed 8086 times
Spoiler:
-
dell_insp.png (6.64 KiB)Viewed 8086 times
Spoiler:
: Скриншоты подводят убедительную базу в сторону моей точки зрения против теней, прозрачности и прочих свистоперделок. Также подтверждают давно выдвинутый Serge тезис о провальной скорости чтения из видеопамяти при больших обьемах.Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
Хорошие скриншоты, интересные данные.
Интересно, а что будет, если загрузить старый файл pattern в новую версию?
Интересно, а что будет, если загрузить старый файл pattern в новую версию?
Будут неправильные позиции начиная с 3-ей. Последние будут пустыми. Файл вообще с запасом.SoUrcerer wrote:Интересно, а что будет, если загрузить старый файл pattern в новую версию?
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
SVN r. 3446 - добавлен бенчмарк для получения данных с помощью регистра GS (прочитать область экрана).
Очередные тесты на самом дохлом и самом быстром доступном мне оборудовании.
Roverbook U800
Dell Inspiron N7010 (Intel i5)
Как можно заметить на более мощном Dell разница между ф.36 и чтением через GS минимальна. Вероятно сказывается большой кэш процессора.
Минус метода с использованием GS вместо ф.36, то что курсор попавший в захватываемую зону будет отражен в буфере, а если он еще и двигаться будет в этот момент, то будут его ошметки размазанные по случайным участкам. В общем кроме Screenshooter пока сложно придумать применение данному способу захвата изображения.
Очередные тесты на самом дохлом и самом быстром доступном мне оборудовании.
Roverbook U800
Spoiler:
-
rover.png (3.4 KiB)Viewed 7989 times
Spoiler:
-
dell.png (3.41 KiB)Viewed 7989 times
Минус метода с использованием GS вместо ф.36, то что курсор попавший в захватываемую зону будет отражен в буфере, а если он еще и двигаться будет в этот момент, то будут его ошметки размазанные по случайным участкам. В общем кроме Screenshooter пока сложно придумать применение данному способу захвата изображения.
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!

Мой старый тест 07 марта 2013 из этой же темы viewtopic.php?p=46811#p46811 (курсор вне окна)
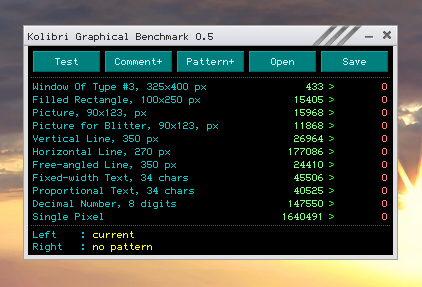
И новый тест. Ядро r3596, результаты поразительные, проседание только в рисовании вертикальных линий.
Может и остальные, повторите этот тест. Интересно было бы если бы кто-то прогнал вначале старую версию Колибри, потом последнюю, чтобы оценить как внесённые за это время изменения отразились на производительности UI.
И новый тест. Ядро r3596, результаты поразительные, проседание только в рисовании вертикальных линий.
-
acer4740g.png (29.13 KiB)Viewed 7932 times
Из хаоса в космос
Оставлю здесь, чтобы не забыть. Есть идея добавить тест для вывода текста в память, который я добавил в ядро ранее. В настоящий момент насколько мне известно фичу используют три программы: текущая и новая версии ICON, HTMLv. Просто самому стало интересно как оно в плане скорости работает (хуже, лучше, также) по сравнению с обычным прямым выводом текста на экран.
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
SVN r. 3782 - добавлен бенчмарк вывода текста ф.4 в память, с последующим выводом ф.65.
В Qemu (по грубым прикидкам) такой вывод дает ускорение в 7-8 раз. Нужно тестировать на реальном железе.
Ускорение получается из-за последовательной записи в видеопамять, в то время как запись просто ф.4 происходит в непоследовательные ячейки.
В Qemu (по грубым прикидкам) такой вывод дает ускорение в 7-8 раз. Нужно тестировать на реальном железе.
Ускорение получается из-за последовательной записи в видеопамять, в то время как запись просто ф.4 происходит в непоследовательные ячейки.
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
Поскольку все настолько заняты разглядыванием буковок в форуме, то я решил протестировать сам.
1) Dell Inspiron
2) eBox
3)Roverbook U800
1) Dell Inspiron
Spoiler:
-
DELL_MGB.png (4.26 KiB)Viewed 8004 times
Spoiler:
-
EBOX_MGB.png (4.2 KiB)Viewed 8004 times
Spoiler:
-
U800_MGB.png (4.25 KiB)Viewed 8004 times
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
А теперь фокус-покус (следите за руками), берем код:
и меняем местами два буфера
Получаем:
1) Dell Inspiron
2) eBox
3) Roverbook U800
С чем связано такое поведение ядерного кода не понятно.
Spoiler:
Code: Select all
start:
mcall 68,11
mcall 68,12,8+9*6*38*4 ; 7352
mov [text_scren_buffer],eax
mcall 68,12,8+9*6*38*4 ; 8216
mov [text_scren_buffer2],eaxSpoiler:
Code: Select all
start:
mcall 68,11
mcall 68,12,8+9*6*38*4 ; 8216
mov [text_scren_buffer2],eax
mcall 68,12,8+9*6*38*4 ; 7352
mov [text_scren_buffer],eax1) Dell Inspiron
Spoiler:
-
dell_mgb2.png (4.28 KiB)Viewed 8002 times
Spoiler:
-
ebox_mgb2.png (4.21 KiB)Viewed 8002 times
Spoiler:
-
u800_mgb2.png (4.58 KiB)Viewed 8002 times
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
Однако все равно прирост на слабых машинах для ф.4 с выводом в память и последующим выводом буфера весьма значителен, чем просто вывод текста на экран.
Всем чмоки в этом проекте! Засуньте эти 11 лет себе в жопу!
А в чём там разница в результатах, с порядком выделения буферов ?

Странно, что Fixed-width Text(m) и Proportional Text(m) имеют стабильные показатели на всех компьютерах, которыми меняются при обмене буферами.
Who is online
Users browsing this forum: No registered users and 4 guests