Page 4 of 17
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 1:36 pm
by art_zh
Mario
Контроллер памяти контролирует память.
Предвыборкой данных занимается контроллер кэша.
И понятно, что для горизонтальной строчки процент попаданий будет почти 100%, отсюда и скорость.
Только к фреймбуферу это не имеет отношения - он не кэшируется (к тому же на чистой
записи кэш особого прироста не дает)
Весь наблюдаемый эффект - из-за чтения кэшируемой строчки байтов
здесь
Экранная таблица [_WinMapAddress], на кусок из которой указывает ebp, занимает столько байт, сколько пикселей на экране. И при каждой графической операции происходит их загрузка в кэш, откуда приходится вытряхивать что-то действительно полезное...
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 2:45 pm
by Serge
art_zh
Марат прав, дело именно в последовательном доступе. Видеопамять
write-combined (не знаю как удачно перевести). Доступ не кешируется, но операции записи накапливаются в store buffers и сбрасываются пакетами. К тому же для неё разрешена неупорядоченная запись. Всё это даёт неплохой прирост при последовательной записи. По этой же причине запись в видеопамять намного быстрее чтения.
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 3:01 pm
by Mario
Я в свое время столкнулся с таким же, когда реализовывал IDE PATA DMA. При записи и чтении одиночных секторов (и даже кластеров) прироста по сравнению с PIO практически нет. Потому реализовал алгоритм, который ищет последовательные блоки и скидывает их объединяя до 64 секторов в один запрос при записи. При чтении же считывается сразу до 16 секторов экспериментальное значение, чтобы избежать большого штрафа (чтение неиспользуемых секторов) и получить ускорение.
Может и здесь применить что-то подобное?
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 3:20 pm
by art_zh
Serge
Возможно. Хотя и не очевидно. С чего бы тогда взяться 20%-ному приросту, если данные записи все равно так или иначе буферизуются в порядке живой очереди?
Я все-таки поробую запретить кэширование экранной таблицы, тогда ясно будет.
Mario wrote:Может и здесь применить что-то подобное?
о том и речь: реальное ускорение будет при буферизации оконной графики с последующим "построчным" копированием окна в главный фреймбуфер.
Нет блиттера - и movsd сгодится...
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 4:09 pm
by CleverMouse
qemu при настройках по умолчанию эмулирует видеокарту Cirrus, не знающую про 32-битные видеорежимы - только 8-, 16- и 24-битные. Я считаю, что не стоит выкидывать код для 24-битного VESA2 - в том числе выкидывать из бинарного файла ядра условной компиляцией - по крайней мере, пока не будет 16-битного VESA2.
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 4:49 pm
by art_zh
CleverMouse wrote:qemu при настройках по умолчанию эмулирует видеокарту Cirrus, не знающую про 32-битные видеорежимы - только 8-, 16- и 24-битные. Я считаю, что не стоит выкидывать код для 24-битного VESA2 - в том числе выкидывать из бинарного файла ядра условной компиляцией - по крайней мере, пока не будет 16-битного VESA2.
Синьорита,
Вы дарите нашему занудному форуму всего пять с половиной слов в день,
(в среднем)
Но каждое Ваше слово - чистое золото!
Всё, решение принято - транк остается многорежимным, весь экстрим переносится в экспериментальную
Колибри-А, откуда желающие всегда могут выудить для себя что-нибудь полезное.
(голосование и обмен мнениями продолжаются)
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 5:04 pm
by Mario
art_zh wrote:
о том и речь: реальное ускорение будет при буферизации оконной графики с последующим "построчным" копированием окна в главный фреймбуфер.
Нет блиттера - и movsd сгодится...
Пока несколько не понятно какой размер памяти стоит выделять под такую операцию. Выделять такой-же объем как сама отображаемая видеопамять - жаба давит.
Хотя с другой стороны именно так я в свое время ускорил запись в VGA режиме. Вернее там уже был буфер, но память записывалась попиксельно, а буфер использовался исключительно для операций чтения - возвращения 24-х битового значения точки. Учитывая, что для каждого цветового семпла приходилось устанавливать свой флаг, то запись производится в три захода для каждой точки. Если же записывать не одну точку в 4 бита а все 32 бита, то ускорение получилось значительное. А потом вообще реализовал запись областями. Т.е. запоминаются предельные границы измененного прямоугольника, они выравниваются на границу dword записываемого в VGA. Дальше копируется построчно весь блок.
В случае 24-х и 32-х битного режима для горизонтальной линии вероятно придется копировать непрерывный кусок в экран. Не сожрут ли накладные расходы по пересылке пустых dword получающийся прирост еще вопрос неопределенный. Может статься, что и овчинка выделки не окупит.
Re: Оптимизация ядерной графики
Posted: Wed Nov 24, 2010 7:33 pm
by art_zh
Mario
Да, если нет аппаратного ускорения (по крайней мере в виде пакетных пересылок данных), то из всей затеи выйдет пшик.
Или надо делать очень громоздкую проверку контента, чтобы не перегружать всё окно ради одной точки.
Serge
В версии 1710 я сделал экранную карту некэшируемой. В результате производительность графики упала в разы.
Особенно заметно замедление на 2-мерных примитивах: прямоугольник - в 20 раз, рисунок - в 24, окно - в 17.
Линии теперь рисуются с одинаковой скоростью: вертикальная - 13.9тыс линий в секунду (почти вдвое медленнее), горизонтальная -18тыс (но она на 30% короче), наклонная - 13700 (в ней больше точек).
Текстовый вывод замедляется почти в 4 раза, случайные пиксели - в 2.3 раза.
Так что дело все-таки не во write-combined буфере вывода, а в системном кэше, однозначно.
(кстати, в этом можно было убедиться и не ковыряя ядро - просто прогони тест MGB при разных видеорежимах - чем меньше точек, тем быстрее работает)
Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 12:14 am
by Serge
art_zh
Ну естественно. У тебя процессор просто встал на чтении карты. По одному байту за цикл. Некешируемая память - никакой предвыборки, запись и чтение строго упорядоченны. Скорость видеопамяти здесь уже не играет роли.
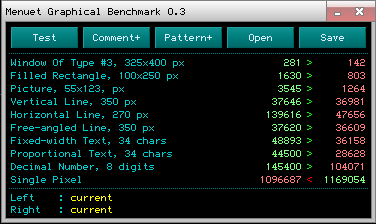
-
00.png (8.47 KiB)
Viewed 5535 times
слева транк, справа видеопямять без write combining. Видно что сильнее всего просела hline со строго последовательным доступом. А теперь сравним:
vline 350*36981=12 943 350
hline 270*47656=12 867 120 - обе близко к результатам Single Pixel.
для сравнения write combining hline
139616*270*4 =143.8 Mb/c близко максимальной скорости записи.
Кстати после первого вызова hline и vline данные из оконной карты будут в кеше L2 и сравнительное влияние промахов кеша на скорость при последующих вызовах очень сильно уменьшится.
Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 2:02 am
by art_zh
Serge
Да, предвыборка экранной карты может где-то помочь при выводе фигур, символов, горизонтальных и (возможно) наклонных линий, но это - малосущественные детали.
Главное - что эксперимент однозначно показал: основная причина всех задержек - это малоэффективная проверка попадания каждого пикселя в открытую область рисования. Там, где эти проверки можно минимизировать/кэшировать, скорость зашкаливает за 100 мегапикселей в секунду, тогда как совсем некэшируемые проверки тормозят процесс до 2-4 Мпс.
Еще раз проимхою свою мысль: попиксельная карта экрана - это идиотизм в клинической стадии, и кэширование этой таблицы только усугубляет проблему, а не снимает ее.
Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 2:13 am
by Mario
art_zh wrote:Serge
Еще раз проимхою свою мысль: попиксельная карта экрана - это идиотизм в клинической стадии, и кэширование этой таблицы только усугубляет проблему, а не снимает ее.
Пока что никто не реализовал лучше. Особенно чтобы в тесте заметно было.
В свое время Иван Поддубный переписал на пересылку DWORD и WORD, в Menuet вообще было побайтная пересылка - скорость возросла в 1,5-2 раза.
Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 2:22 am
by Serge
art_zh
Вот как раз однозначно и не показал. Смотри мои результаты выше. hline с транка практически упирается в скорость записи для моей системы.
Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 3:28 am
by art_zh
Serge wrote:Вот как раз однозначно и не показал. Смотри мои результаты выше. hline с транка практически упирается в скорость записи для моей системы.
1)Ты убрал write-combining, и скорость hline села
в 3 раза. Я убрал кэширование -
падение в 21 раз. И какой эффект эффектнее?
2) мою hline-скорость после пляски с бубном удалось-таки поднять на 20% по сравнению с транком (см. скриншот на 3-й странице). И сдается мне, что это еще не предел.
Но опять-таки, это только для hline (и с оговорками - для некоторых горизонтально-заливаемых фигур). Только для них кэширование экранной карты имеет смысл благодаря очень высокому проценту попаданий. Отключи кэширование (при побайтной проверке таблицы) - и hline в точности сравняется в скорости с vline. Надеюсь, хоть с этим вы с
Mario согласитесь ?
3) На всем остальном кэширование дает очень скромный прирост (в 2-4 раза) по сравнению с проверкой по некэшируемой байт-таблице. И это - на моторах с
мегабайтыми кэшами! Чем короче кэш - тем скромнее фифект.
4) Но суть то и не в этом (ну казалось бы работает - и кэш с ним, пусть работает). Но ведь эта экранная карта занимает до 9Мб памяти, она даже в Феномовский кэш целиком не влезет. И даже во времена VGA не влезала (тогда кэшей таких не было). Значит, все разговоры о том, что ядро Колибри "почти целиком" сидит в процессорном кэше - пустая болтовня. Могло бы там сидеть, но его оттуда сдувает любое переключение окошка...
5) Может, и это оставим как оно есть?
Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 10:46 am
by Mario
art_zh wrote:
5) Может, и это оставим как оно есть?
Не, хочу обидеть, но...

я отписал об этом вероятно самым первым.

Re: Оптимизация ядерной графики
Posted: Thu Nov 25, 2010 12:59 pm
by Serge
art_zh
9 Мб ??? У нас таких режимов нет. _WinMapAddress - 1 байт на пиксель.
3) Отключи кэширование (при побайтной проверке таблицы) - и hline в точности сравняется в скорости с vline. Надеюсь, хоть с этим вы с Mario согласитесь ?
Я не сомневаюсь, что сравняются. Обе намертво упёрлись в чтение из некешированной таблицы. Для процессора это жуткий тормоз. То есть с отключённым кешированием процессор еле выдаёт 4.8 мегапикселя в секунду.
Сделай тесты без проверки таблицы или вообще с прямым доступом к видеопамяти и ты получишь близкие результаты и для vline и для single pixel. Обе функции показывают максимальную скорость заполнения видеопамяти при произвольном доступе. И обе в неё упираются в обычном ядре.
Сравнительные результаты MGB для vline и hline в обычном ядре очень слабо зависят от кеша. После первого вызова функций все необходимые данные из байтовой таблицы будут в L1 кеше. 270 байт hline и 350*16 или 350*32 hline по сравнению 64 кБ L1 data на Атлонах совсем немного. В этих тестах процессор работает с максимально возможной скоростью и на 99.9% процентов не вылазит из L1 кеша. По этому разница в скорости заполнения vline и hline вызвана не промахами кеша, их там очень очень мало, а особенностями работы комбинированной записи.